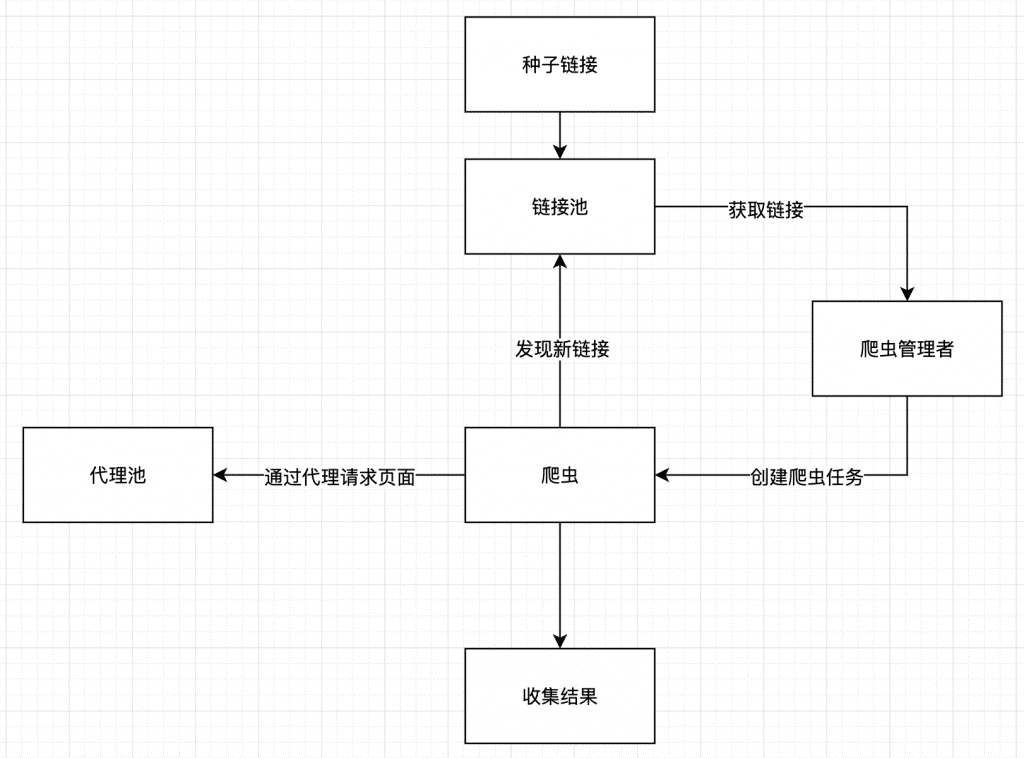
 上面这个图是我设计的爬虫架构,这个架构逻辑比较简单。
上面这个图是我设计的爬虫架构,这个架构逻辑比较简单。
首先是链接池,链接池存储需要爬取的网页链接,每个链接有当前爬取状态,尝试次数等信息,爬取状态分为:waiting(等待),going(正在进行),success(爬取成功),fail(爬取失败)。链接的默认状态是waiting,当爬虫正在爬取这个链接的内容的时候,链接进入going状态,链接内容爬取成功进入success状态,爬取失败进入fail状态。链接的另一个参数是尝试次数,当链接爬取失败则尝试次数加1并再次进入waiting状态,设定尝试次数阈值,比如设定阈值为3,当尝试次数超过3次,则进入fail状态。
爬虫管理者负责创建爬虫任务,我们可以创建一个task来定期运行爬虫管理者。爬虫管理者从爬虫池中选取一定数量的处于waiting状态的链接,创建爬虫任务。
爬虫任务接受一个目标链接,然后针对链接的格式运行对应的解析器。如果发现新的目标链接,则将新发现的链接放入链接池。这个地方需要注意的是爬虫在请求链接内容的时候,要使用代理,这样可以防止同一个ip频繁请求被封的情况。
刚开始链接池是空的,所以我们需要放入第一个目标链接,这样爬虫会不断的发现新链接,然后将新链接作为目标链接再次爬取内容,如果效果好的话,爬虫会一直运行知道没有新的链接发现未知。